파이썬 로또번호 크롤링
로또번호 생성기 사이트를 제작하면서 로또번호를 어떻게 생성할까 고민해 보았습니다.
저도 매주 로또를 사고 그 로또가 1등에 당첨되어 인생한방을 항상 꿈꾸는 사람중 한명입니다.
그런데 로또 1등에 당첨되기는 참 하늘에 별따기보다 더 어려운거 같습니다 ㅠㅠ
무튼, 확률이 높은 번호를 뽑을려면 어떻게 해야될까를 생각하다가 문득 든 생각이 현재까지 1등 당첨된 로또번호 데이터를 기반으로 로또를 생성하면 그냥 무작위로 생성하는거보다는 확률이 그나마 조금이라도 높지 않을까 생각 되었습니다.
그래서 로또번호 생성기 웹사이트를 제작하기 전에 준비 단계로 로또번호 데이터를 모으는 작업을 하였습니다.
데이터를 하나하나 수동으로 모으기에는 너무 많은 데이터라 자동으로 모으는 방법으로 파이썬으로 크롤링하여 데이터를 수집 하였습니다.
로또번호 생성기 링크
https://noticedev.com/lotto/generators
로또번호 생성기 - Notice Lotto
로또번호 제외 생성기 제외할 로또번호를 직접 선택하여 로또번호를 생성할 수 있습니다. 번호 생성 시 선택한 번호는 제외됩니다.
noticedev.com
urllib 의 requests 모듈
파이썬에서는 웹과 관련된 데이터를 쉽게 다룰 수 있도록 urllib 모듈을 제공합니다.
urllib 는 파이썬을 설치하시면 import 만 하여 바로 사용하시 수 있습니다.
import urllib
urllib.request 모듈은 다이제스트 인증, 리디렉션, 쿠기 등과 같은 URL 이나 HTTP 를 여는데 도움이 되는 함수와 클래스를 정의합니다. 즉 urllib.request 모듈을 사용하면 간단하게 웹페이지 요청 및 데이터를 가져오는 것이 가능합니다.
(웹사이트 내의 한 페이지의 html 를 모두 긁어온다고 이해하시면 됩니다.)
urllib.request 의 urlopen 함수
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urlopen 함수는 string 이나 request 객체인 URL 을 open 합니다. 더 많은 옵션들이 있지만 대부분 URL 의 페이지 내용을 읽어오는데 많이 사용합니다.
예시를 통해 확인해봅시다.
import urllib.request as ur
URL = "https://noticedev.com/lotto/generators/"
htmlpage = ur.urlopen(URL).read()
print(htmlpage.decode('utf-8'))
# 아래 결과
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<meta http-equiv="content-language" content="ko" />
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.2.2/dist/css/bootstrap.min.css" integrity="sha384-Zenh87qX5JnK2Jl0vWa8Ck2rdkQ2Bzep5IDxbcnCeuOxjzrPF/et3URy9Bv1WTRi" crossorigin="anonymous">
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/4.7.0/css/font-awesome.min.css">
<link rel="stylesheet" type="text/css" href="/css/style.css">
<link rel="apple-touch-icon" sizes="120x120" href="/apple-touch-icon.png">
<link rel="icon" type="image/png" sizes="32x32" href="/favicon-32x32.png">
<link rel="icon" type="image/png" sizes="16x16" href="/favicon-16x16.png">
<link rel="manifest" href="/site.webmanifest">
<link rel="mask-icon" href="/safari-pinned-tab.svg" color="#5bbad5">
<meta name="msapplication-TileColor" content="#da532c">
<meta name="theme-color" content="#ffffff">
<script async src="https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-7650634137819060"
crossorigin="anonymous"></script>
<meta name="naver-site-verification" content="ccc4785c2f5bc48a97f447fd9c9107aeec01e788" />
<script async custom-element="amp-auto-ads"
src="https://cdn.ampproject.org/v0/amp-auto-ads-0.1.js">
</script>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.2.2/dist/js/bootstrap.bundle.min.js" integrity="sha384-OERcA2EqjJCMA+/3y+gxIOqMEjwtxJY7qPCqsdltbNJuaOe923+mo//f6V8Qbsw3" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/@popperjs/core@2.11.6/dist/umd/popper.min.js" integrity="sha384-oBqDVmMz9ATKxIep9tiCxS/Z9fNfEXiDAYTujMAeBAsjFuCZSmKbSSUnQlmh/jp3" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.2.2/dist/js/bootstrap.min.js" integrity="sha384-IDwe1+LCz02ROU9k972gdyvl+AESN10+x7tBKgc9I5HFtuNz0wWnPclzo6p9vxnk" crossorigin="anonymous"></script>
<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
<title>로또번호 생성기 - Notice Lotto</title>
<meta name="description" content="로또번호를 자동으로 생성합니다. 현재까지 당첨된 로또번호를 분석하여 생성합니다. 생성된 로또번호를 표시합니다. Notice Lotto"/>
<meta name="keywords" content="로또번호 생성기, 로또번호 추출기, 로또번호 생성목록"/>
<meta name="author" content="Notice Dev"/>
<meta name="og:site_name" content="Notice Lotto"/>
<meta name="og:title" content="로또번호 생성기"/>
<meta name="og:description" content="로또번호를 자동으로 생성합니다. 현재까지 당첨된 로또번호를 분석하여 생성합니다. 생성된 로또번호를 표시합니다. Notice Lotto"/>
<meta name="og:type" content="website"/>
<meta name="og:url" content="https://www.noticedev.com/lotto/generators/"/>
<link rel="canonical" href="https://www.noticedev.com/lotto/generators/"/>
...
제가 만든 로또번호 생성기의 한 페이지를 읽어 왔습니다.
URL 을 넣으면 HTML 을 반환하고 read() 를 통해서 읽을 수 있습니다.
decode('utf-8') 로 디코딩 하지 않으면 디코딩 된 페이지의 결과가 보이지 않기 때문에 html 코드를 확인하기가 상당히 어렵습니다.
아래는 디코딩 되지 않은 결과입니다. 이렇게 나오는구나 하고 참고만 하시기 바랍니다.
b'<!DOCTYPE html>\r\n<html>\r\n<head>\r\n <meta charset="UTF-8">\r\n <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">\r\n <meta http-equiv="content-language" content="ko" />\r\n\r\n <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.2.2/dist/css/bootstrap.min.css" integrity="sha384-Zenh87qX5JnK2Jl0vWa8Ck2rdkQ2Bzep5IDxbcnCeuOxjzrPF/et3URy9Bv1WTRi" crossorigin="anonymous">\r\n <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/4.7.0/css/font-awesome.min.css">\r\n <link rel="stylesheet" type="text/css" href="/css/style.css">\r\n\r\n <link rel="apple-touch-icon" sizes="120x120" href="/apple-touch-icon.png">\r\n <link rel="icon" type="image/png" sizes="32x32" href="/favicon-32x32.png">\r\n <link rel="icon" type="image/png" sizes="16x16" href="/favicon-16x16.png">\r\n <link rel="manifest" href="/site.webmanifest">\r\n <link rel="mask-icon" href="/safari-pinned-tab.svg" color="#5bbad5">\r\n <meta name="msapplication-TileColor" content="#da532c">\r\n <meta name="theme-color" content="#ffffff">\r\n\r\n <script async src="https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-7650634137819060"\r\n crossorigin="anonymous"></script>\r\n\r\n <meta name="naver-site-verification" content="ccc4785c2f5bc48a97f447fd9c9107aeec01e788" />\r\n\r\n <script async custom-element="amp-auto-ads"\r\n src="https://cdn.ampproject.org/v0/amp-auto-ads-0.1.js">\r\n </script>\r\n\r\n
Beautifulsoup4 설치
Beautiful Soup 은 HTML 및 XML 파일에서 데이터를 가져오는 python 라이브러리 입니다.
선호하는 파서를 이용하여 구문 분석 트리를 탐색, 검색 및 수정 등의 방법을 제공합니다.
보다 자세한 내용은 아래 beautifulsoup doc 링크를 참조하시기 바랍니다.
https://beautiful-soup-4.readthedocs.io/en/latest/#kinds-of-objects
Beautiful Soup Documentation — Beautiful Soup 4.4.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call unicode() or str() on a BeautifulSoup object, or a Tag within it: str(soup) # ' I linked to example.com ' unicode(soup.a) # u' I linked to example.com ' The str() functio
beautiful-soup-4.readthedocs.io
beautifulsoup 를 설치하는 방법 pip(Pip Installs Packages) 를 이용하여 설치하면 됩니다.
pip install beautifulsoup4
이렇게 하면 beautifulsoup 의 설치는 완료 되었습니다.
beautifulsoup4 를 이용한 크롤링
beautifulsoup 은 다양한 파서를 이용하여 페이지를 추출 및 가공할 수 있습니다.
저는 html 페이지를 크롤링할 것이기 때문에 'html.parser' 를 사용하도록 하겠습니다.
아래의 코드를 이용하면 urllib.request 를 통해서 읽어온 html 과 같은 결과를 확인할 수 있습니다.
import urllib.request as ur
from bs4 import BeautifulSoup
URL = "https://noticedev.com/lotto/generators/"
bs = BeautifulSoup(ur.urlopen(URL).read(), 'html.parser')
print(bs)
로또번호 크롤링을 위해서는 동행복권 사이트의 로또번호가 나오는 페이지를 읽어와야겠죠?
동행복권의 로또번호가 있는 페이지는 여기입니다.
출처 - 동행복권
https://dhlottery.co.kr/gameResult.do?method=byWin
로또6/45 - 회차별 당첨번호
1084회 당첨결과 (2023년 09월 09일 추첨) 당첨번호 8 12 13 29 33 42 1084회 순위별 등위별 총 당첨금액, 당첨게임 수, 1게임당 당첨금액, 당첨기준, 비고 안내 순위 등위별 총 당첨금액 당첨게임 수 1게임
dhlottery.co.kr
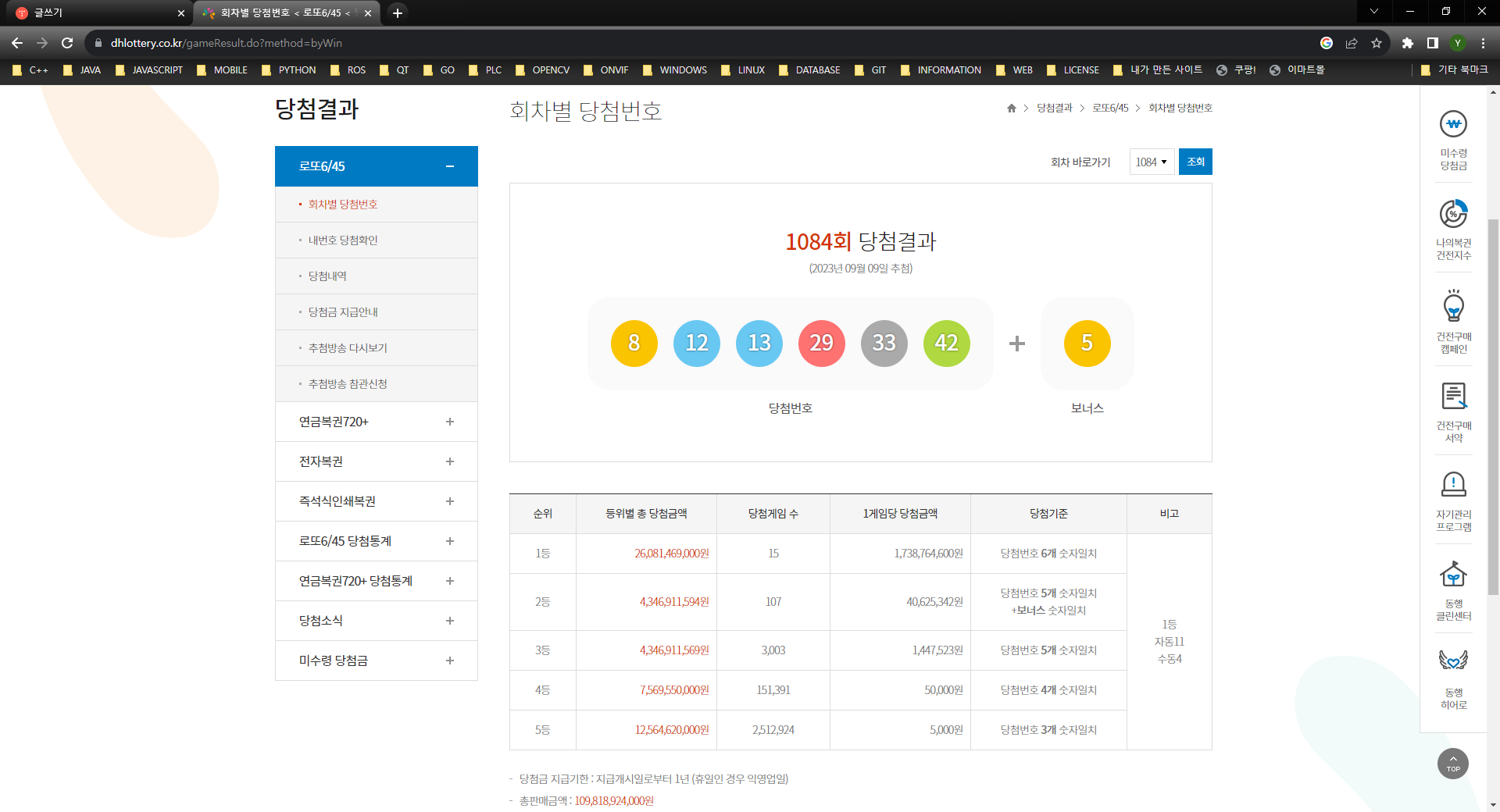
그럼 이제 동행복권의 로또번호가 나오는 페이지를 읽어보도록 하겠습니다.
import urllib.request as ur
from bs4 import BeautifulSoup
URL = "https://www.dhlottery.co.kr/gameResult.do?method=byWin"
bs = BeautifulSoup(ur.urlopen(URL).read(), 'html.parser')
print(bs)
# 아래 결과
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="utf-8"/>
<meta content="동행복권" id="utitle" name="title"/>
<meta content="동행복권 1084회 당첨번호 8,12,13,29,33,42+5. 1등 총 15명, 1인당 당첨금액 1,738,764,600원." id="desc" name="description"/>
<title>로또6/45 - 회차별 당첨번호</title>
<title>동행복권</title>
<meta content="IE=edge" http-equiv="X-UA-Compatible"/>
<link href="/images/common/favicon.ico" rel="shortcut icon" type="image/x-icon"/>
<link href="/images/common/favicon.ico" rel="icon" type="image/x-icon"/>
<script src="/js/jquery-1.9.1.min.js" type="text/javascript"></script>
<script src="/js/jquery-ui.js" type="text/javascript"></script>
<script charset="utf-8" src="/js/common.js" type="text/javascript"></script>
<script type="text/javascript">
...
정상적으로 페이지를 읽어온 것이 확인 되었습니다.
그럼 이제 로또번호 생성기를 제작에 기반이 되는 필요한 데이터들을 읽어오도록 하겠습니다.
해당 페이지의 HTML구조에 맞춰서 데이터를 추출해야 되기 때문에 구조를 확인하여 원하는 데이터만 추출하도록 합니다.
구조를 확인하는 한가지 팁을 드리자면 크롬이나 IE 에서 HTML 데이터를 확인하기 위해 개발자 도구를 사용합니다.
F12 를 누르게 되면 개발자 도구가 나타나는데 여기서 Elements 탭을 클릭하게 되면 해당 페이지의 HTML 코드를 확인하실 수 있습니다.
그리고 CTRL + SHIFT + C 를 누르고 페이지에서 원하는 부분에 마우스를 클릭하게 되면 개발자 도구의 HTML 에서 해당 영역으로 이동하여 선택한 부분의 코드를 보여줍니다.
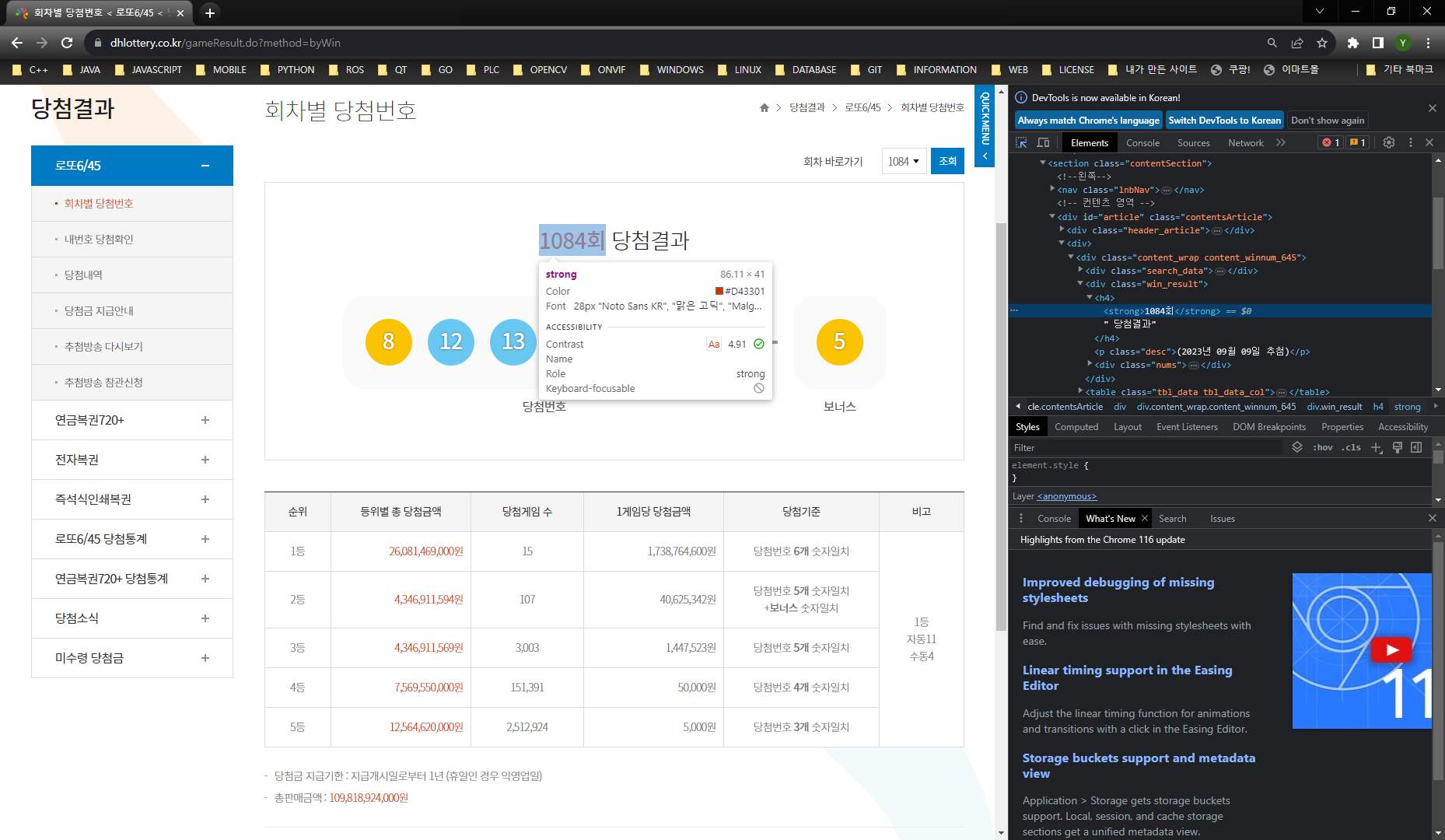
여기서 필요한 데이터는 회차, 추첨일, 로또당첨번호, 보너스번호 이렇게 4가지 입니다.
각 데이터가 있는 곳을 명시하는 태그를 파악하여 크롤링하도록 하거나 전체구조를 파악하여 차례대로 해당 부분을 찾아가도록 크롤링하면 되는데 저는 명시하는 태그를 사용하여 크롤링하도록 하겠습니다.
...
<div class="win_result">
<h4><strong>1084회</strong> 당첨결과</h4>
<p class="desc">(2023년 09월 09일 추첨)</p>
<div class="nums">
<div class="num win">
<strong>당첨번호</strong>
<p>
<span class="ball_645 lrg ball1">8</span>
<span class="ball_645 lrg ball2">12</span>
<span class="ball_645 lrg ball2">13</span>
<span class="ball_645 lrg ball3">29</span>
<span class="ball_645 lrg ball4">33</span>
<span class="ball_645 lrg ball5">42</span>
</p>
</div>
<div class="num bonus">
<strong>보너스</strong>
<p><span class="ball_645 lrg ball1">5</span></p>
</div>
</div>
</div>
...
제가 필요한 부분은 위의 방법으로 찾아보니 위의 코드에서 모두 크롤링이 가능할거 같군요.
그럼 필요한 데이터 별로 크롤링하는 방법에 대해서 간단하게 설명 드리겠습니다.
회차 크롤링
## HTML
# <div class="win_result">
# <h4><strong>1084회</strong> 당첨결과</h4>
# 회차 크롤링
def getRoundId(self) :
roundId = int(self.bs.find('div', {'class': 'win_result'}).find('strong').text.replace('회', ''))
print("회차 : ", roundId)
return roundId
회차 크롤링은 beautifulsoup 의 find 함수를 이용하여 div 태그의 class 가 'win_result' 인 div 태그를 찾은 후 그 내부에서 strong 태그의 내용을 찾습니다. strong 태그의 내용을 찾으면 '1084회' 남게 되므로 여기서 불필요한 '회' 라는 글자를 제거한 후 int 형으로 회차를 반환하도록 합니다.
추첨일 크롤링
## HTML
# <div class="win_result">
# <h4><strong>1084회</strong> 당첨결과</h4>
# <p class="desc">(2023년 09월 09일 추첨)</p>
# 추첨일 크롤링
# import 추가
import re
from datetime import datetime
def getDate(self) :
strDate = self.bs.find('div', {'class': 'win_result'}).find('p', {'class' : 'desc'}).text.replace(u"추첨", "").replace(" ", "")
# parseDate = re.sub(r'\D', '/', strDate)
parseDate = re.sub(r'\W', '', strDate)
parseDate = re.sub(r'\D', '-', parseDate)[:-1]
dateWin = datetime.strptime(parseDate, '%Y-%m-%d')
print("추첨일 : ", dateWin)
return dateWin
추첨일 크롤링은 회차 크롤링에서 'win_result' 내부에 p 태그의 class 가 'desc' 인 내용을 가져와서 '추첨'이라는 단어와 공백을 먼저 제거합니다.
그 다음 정규표현식 re.sub(r'\W', '', strDate) 를 이용하여 양옆의 괄호와 공백을 없애주고 re.sub(r'\D', '-', strDate) 를 이용하여 문자를 '-' 로 변경하고 제일 마지막에 '일' 이라는 문자는 빼고 변수에 할당합니다.
이렇게 하면 남은 데이터가 '2023-09-09' 가 되므로 해당 데이터를 datetime 으로 변환하여 추첨일을 반환합니다.
로또당첨번호 크롤링
# HTML
# <div class="num win">
# <strong>당첨번호</strong>
# <p>
# <span class="ball_645 lrg ball1">8</span>
# <span class="ball_645 lrg ball2">12</span>
# <span class="ball_645 lrg ball2">13</span>
# <span class="ball_645 lrg ball3">29</span>
# <span class="ball_645 lrg ball4">33</span>
# <span class="ball_645 lrg ball5">42</span>
# </p>
# </div>
# 로또당첨번호 크롤링
def getDrwNo(self) :
numWins = []
for i in self.bs.find('div', {'class': 'num win'}).find_all('span'):
print("번호 : ", i.string)
num = re.sub(r'\D', '', i.string)
numWins.append(int(num))
return numWins
로또당첨번호 크롤링은 번호 6개가 규칙적으로 나열되어 있기 때문에 반복문을 이용하여 크롤링하도록 합니다.
먼저 dlv 태그의 class 가 'num win' 인 데이터를 뽑아내서 모든 span 태그의 내용을 반복문으로 순회하도록 합니다. 그런 다음 태그는 필요없이 내용만 추출하면 되므로 i.string 으로 숫자가 적힌 글자를 추출하고 숫자 외에 글자를 모두 제거한 후 int 형으로 변환하여 배열에 담아서 로또당첨번호 전체를 반환하도록 합니다.
보너스번호 크롤링
## HTML
# <div class="num bonus">
# <strong>보너스</strong>
# <p><span class="ball_645 lrg ball1">5</span></p>
# </div>
# 보너스번호 크롤링
def getDrwBonus(self) :
numBonus = int(self.bs.find('div', {'class': 'num bonus'}).find('p').find('span').string)
print("보너스 : ", numBonus)
return numBonus
보너스번호 크롤링은 dlv 태그의 class 가 'num bonus' 인 데이터를 찾아 p 태그 내의 span 태그의 내용을 추출하도록 합니다. 그 외에 다른 내용이 없으므로 해당 데이터를 int 형으로 변환해서 보너스번호를 반환하도록 합니다.
이렇게 크롤링된 데이터들 데이터베이스에 저장하여 로또번호를 생성할 때 사용 하였습니다.
각 번호가 얼마나 출현했는지에 따른 비율, 실제로 로또기계에서 일정한 시간 주기로 추첨되지 않는 점 등을 고려하여 각각의 로또번호를 추출하여 6개의 번호를 생성하도록 하였습니다.
이상입니다.
'개발 > Python' 카테고리의 다른 글
| [TensorFlow] cudart64_110.dll 로드 에러 해결 (0) | 2022.08.22 |
|---|
